Research Overview
Our research group develops AI systems that optimize real-world business objectives, with a particular focus on trustworthy and responsible learning methods. We take a systems-level perspective that spans machine learning, operations research, and statistics to address fundamental challenges in deploying AI in high-stakes domains.
AI models pre-trained on internet data can understand text, code, audio, and video. However, as public data sources become exhausted, it is evident that enabling applications beyond consumer chatbots requires a thoughtful approach to data curation. Mistakes are costly in decision-making problems, and intelligent agents must carefully collect and leverage proprietary data, such as customer feedback and user interactions.
The widespread adoption of AI systems across critical domains has revealed fundamental gaps between academic research and practical deployment. While large language models trained on internet data have achieved impressive capabilities in general tasks, many real-world applications require specialized domain knowledge and careful consideration of reliability, fairness, and safety. Our work addresses these challenges through three key principles:
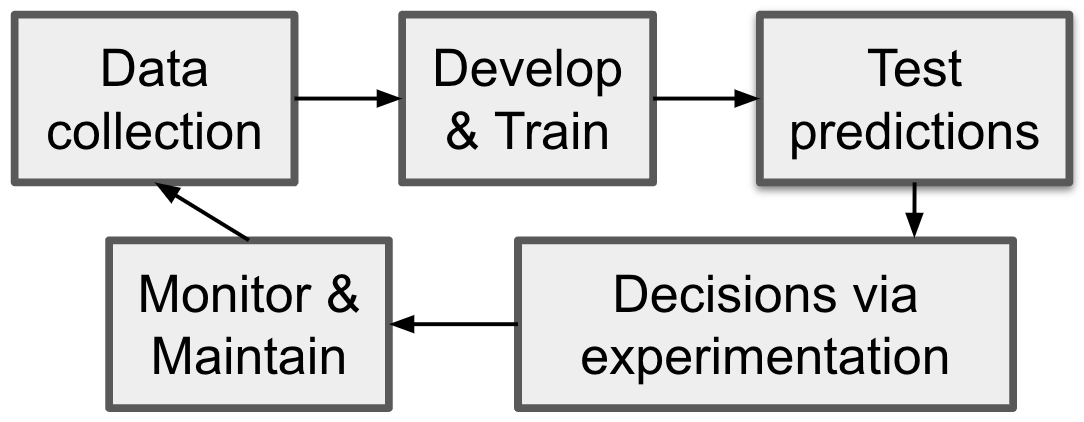
My research group develops trustworthy AI-driven decision-making systems that optimize long-term outcomes. In particular, we take a holistic “process view” of AI systems.
Trustworthy AI
AI systems are omni-present. This is their primary appeal, yet also its biggest shortcoming. During operation, AI systems inevitably encounter tail-inputs and extrapolate in unexpected ways. This phenomena has been widely observed under different names: distribution shift, lack of {fairness, robustness, causality, faithfulness}, and hallucinations.
Scaling internet data is no panacea. Real-world decision-making problems require specialized in-domain datasets, e.g., healthcare, recommender systems, resource allocation. The cost of data collection poses a binding constraint in many disciplines, and we believe new ideas are needed to building intelligent agents. We aim to fill this methodological gap, and develop algorithms that can scale to frontier systems.
Comprehending Uncertainty
Intelligent agents must comprehend their own uncertainty and actively make decisions to resolve it. To advance broad AI capabilities, we must target data collection and synthetic data generation towards areas with high epistemic uncertainty. To bound tail-risk, AI systems must understand when their predictions for anomalous inputs are not trustworthy and delegate to human experts when necessary.
Systems that can reason through epistemic uncertainty based on natural language feedback has been a longstanding challenge. A traditional probabilistic model requires a prior and likelihood over latent variables. But by definition, latents are fundamentally unobservable and often ill-defined.
On the other hand, autoregressive models pre-trained on massive web data exhibit striking predictive capabilities when conditioned on even a small number of demonstrations. Since the 1920’s, De Finetti has advocated for modeling observables rather than latents. We take his predictive view of uncertainty as coming from future data that has not been observed yet. Let us illustrate with a conceptual example that crystallizes our insight (note: the example is made up and clearly devoid of clinical significance).
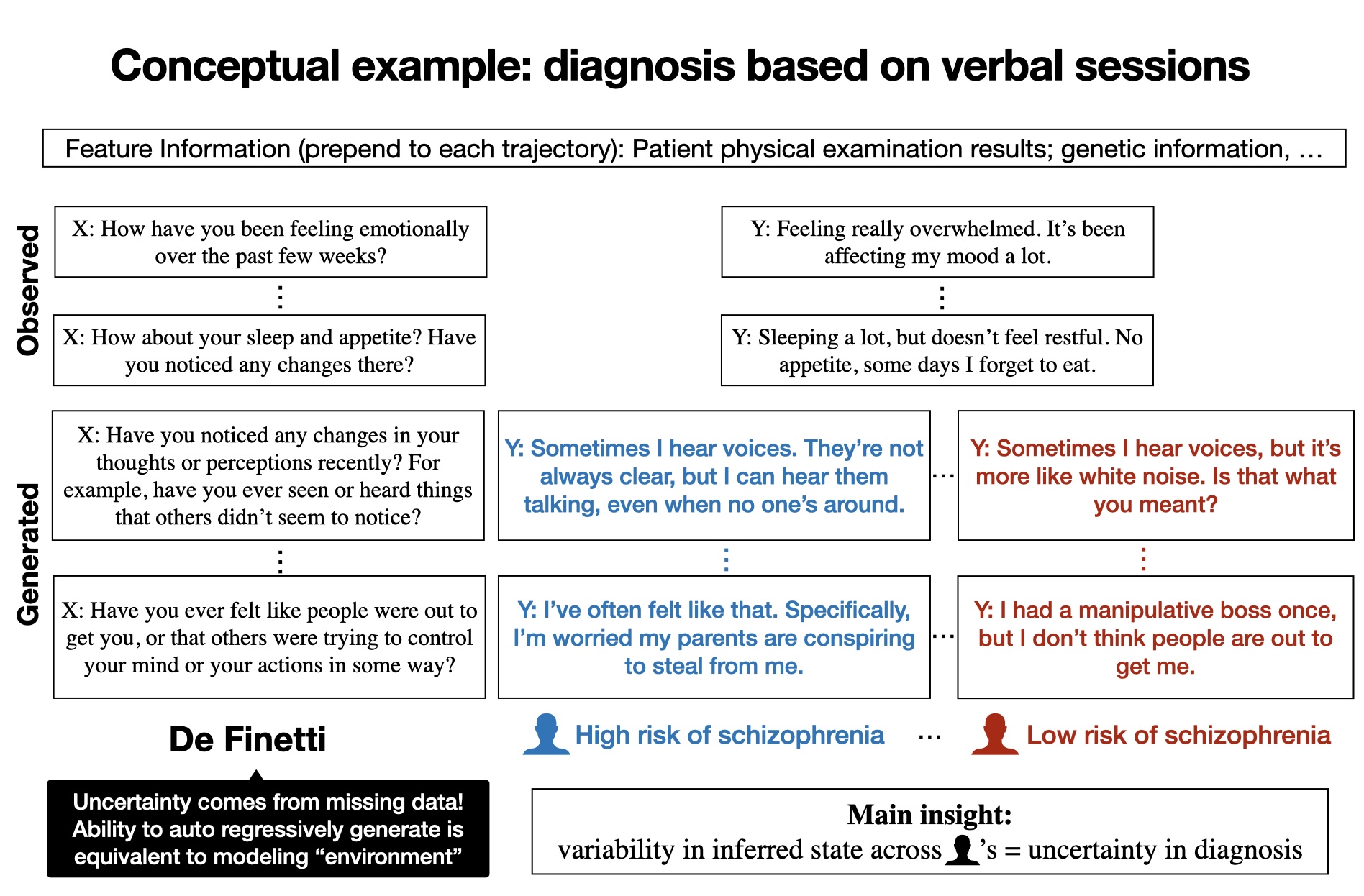
Crucially, the AI agent can updatie beliefs as data is gathered. Unlike cumbersome posterior inference routines for probabilistic models, you can now simply append prior observations to the context of the sequence model. To learn more, watch this recent talk at Simons Institute, and the following recent paper from the group. We are actively working in this space so ping us if you’d like to chat more.
-
Trustworthy AIarXiv:2408.03307 [stat.ML], 2024
Language for distribution shifts
Different distribution shifts require different solutions. Understanding why model performance worsened is a fundamental step for informing subsequent methodological and operational interventions. Heterogeneity in data helps robustness, but the cost of data collection is often a binding constraint. We build a nuanced modeling language for quantifying data heterogeneity (or lack thereof), and use it to make optimally allocate limited resources in the AI production pipeline. To learn more, watch the following NeurIPS tutorial and take a look at the following two papers.

Foundations of distributional robustness
Classical approaches that optimize average-case performance yield brittle AI systems. They fail to i) make good predictions on underrepresented groups, ii) generalize to new environments, even those similar to that seen during training, and iii) be robust to adversarial examples and long-tailed inputs. Yes, even the largest models trained on the entirety of the internet! Despite recent successes, lack of understanding on the failure modes of AI systems highlights the need for models that i) reliably work and ii) rigorous evaluation schemes and diagnostics that maintain their quality.
Our vision is to build robust and reliable learning procedures that make decisions with a guaranteed level of performance over its inputs. My Ph.D. thesis built the statistical
-
Trustworthy AIOperations Research, 2022
AI-driven decisions
Prediction is never the final goal. To align AI-models optimized to predict short-term outcomes with downstream long-term goals, we design scalable computational frameworks for learning operational decisions. We derive algorithms from mathematical principles, but test them using rigorous empirical benchmarking practrices rather than relying on theoretical guarantees in idealized, contrived settings.
Optimization-driven adaptive experimentation
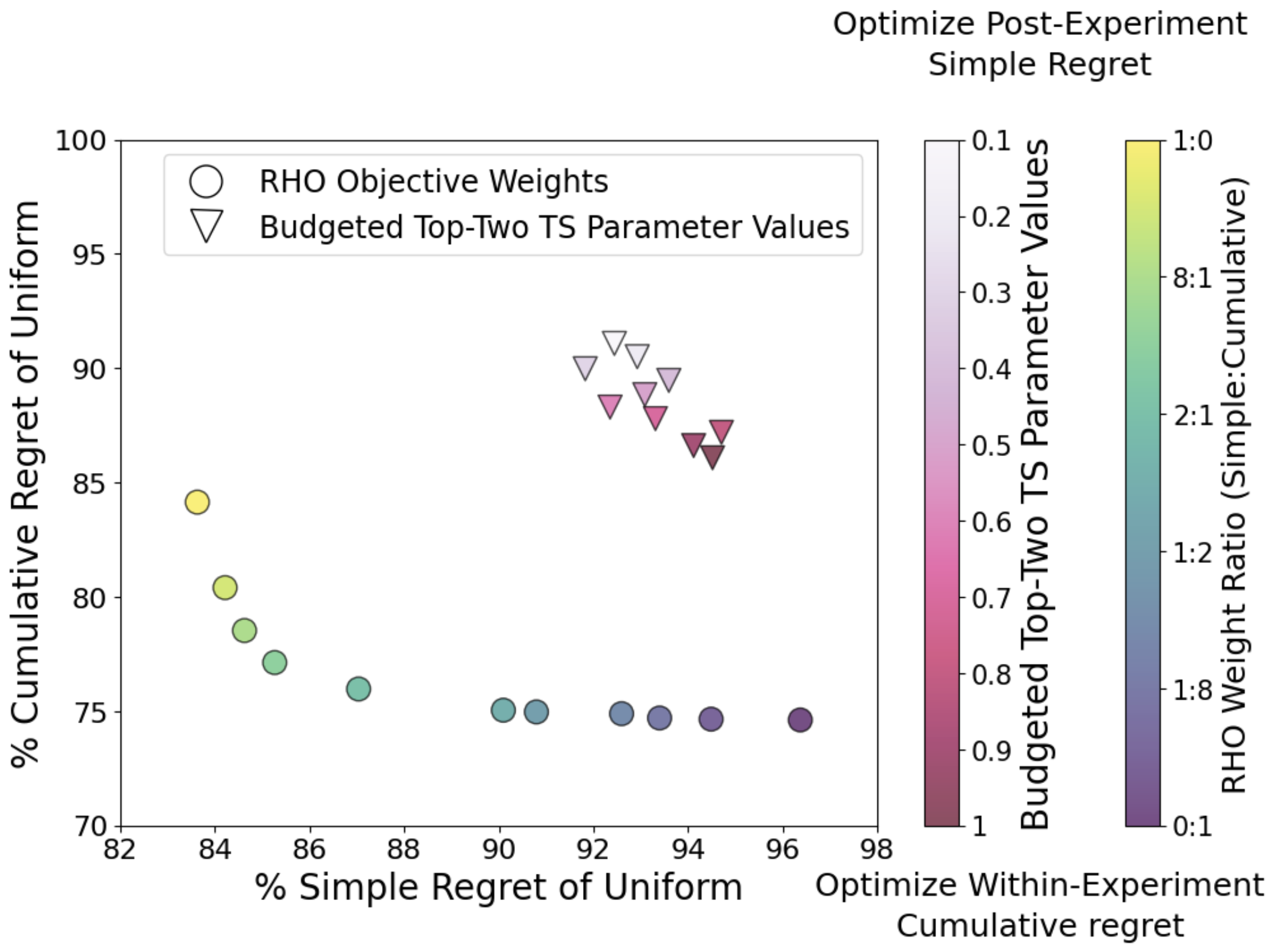
Experimentation is the foundation of scientific decision-making. Adaptive experimentation can significantly improve efficiency by focusing resources on promising treatments, and expand the set of testable scientific hypotheses. However, significant practical challenges remain in applying standard adaptive algorithms:
- Batching, delayed feedback, and short horizons: Bandit algorithms are designed to be updated after every observation, but real-world experiments are conducted with a few large batches and limited adaptivity due to infrastructure constraints and delayed feedback.
- Nonstationarity: Customers at Costco look different on Sunday vs. Monday.
- General objectives and metric constraints: Practitioners care about a wide range of objectives and constraints (within- vs. post-experiment) across multiple outcomes/metrics/rewards.
- Cost/budget constraints: We often want the best treatment while satisfying budget constraints.
The existing algorithm design paradigm requires you to consider a very specific combination of these features and develop a new bandit algorithm tailored to this setting. This is akin to akin to an optimization solver developed for a particular linear program! Naturally, existing algorithms are extremely brittle and often underperform even a non-adaptive A/B test.
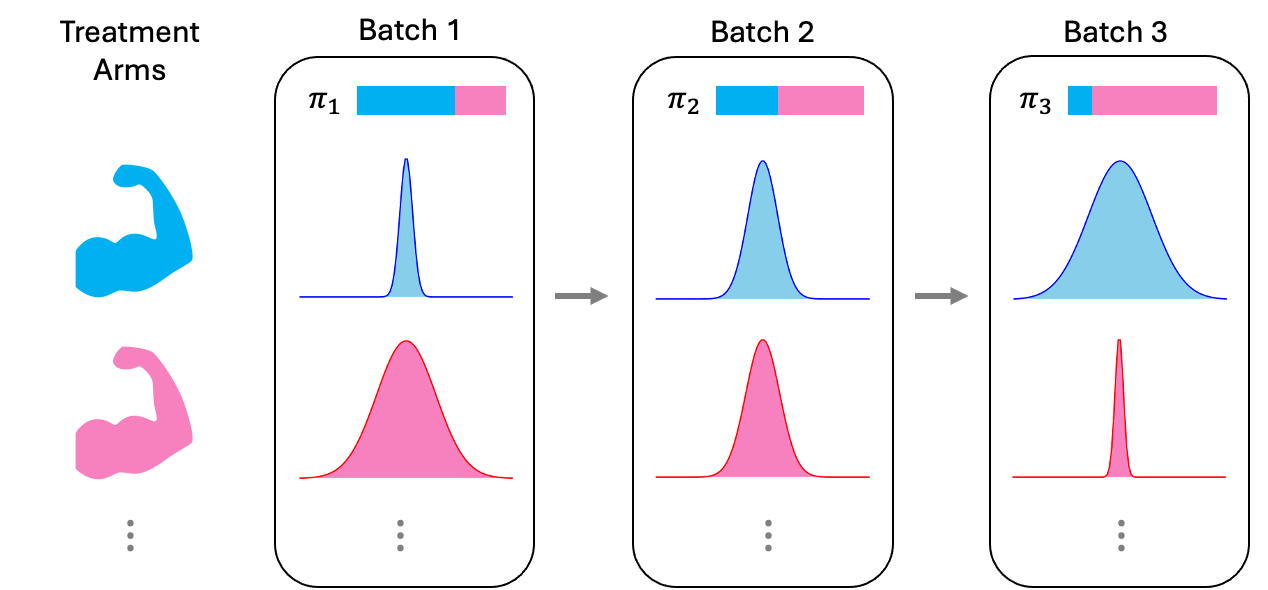
Instead, we develop a mathematical programming framework for developing adaptive experimentation algorithms. We ask the modeler to write down a flexible optimization formulation and use modern machine learning systems to (heuristically) solve for adaptive designs.
How do we do this? A naive formulation of the adaptive experimentation problem as a dynamic program is intractable: individual outcome distributions are unknown and leads to combinatorial actions spaces. Using a batched view, we model the uncertainty around batch-level sufficient statistics necessary to enable the use of modern computational tools (auto-differentiation and SGD, as opposed to human intuition) in designing adaptive algorithms.
-
AI-driven DecisionsarXiv:2408.04531 [cs.LG], 2024
Informed Exploration Using Foundation Models
Real-world decision-making requires the AI agent to continually interact with the environment. This requires combining two different modes of learning: static and interactive. We propose a paradigm of learning where the agent initially relies on the rich world prior available in frontier AI models to balance exploration and exploitation. As data gathered online accrues, the agent must increasingly rely more heavily on them by updating its beliefs.
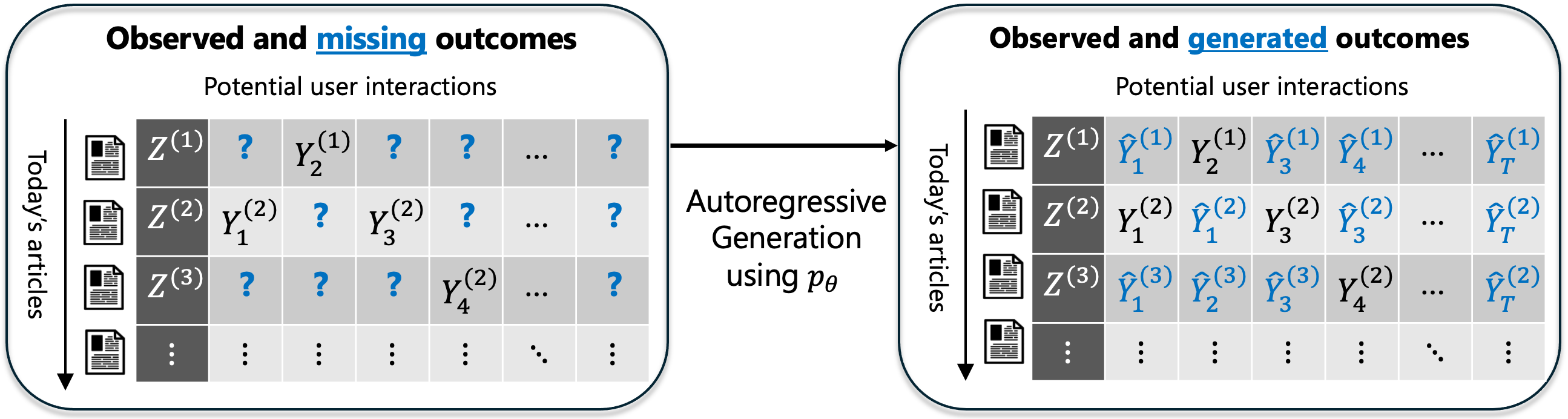
-
AI-driven DecisionsarXiv:2405.19466 [cs.LG], 2025Selected for presentation at the Econometric Society Interdisciplinary Frontiers: Economics and AI+ML conference
AI-based service systems
Recent advances in AI present significant opportunities to rethink the design of service systems with AI at the forefront. Endogeneity presents a key intellectual challenge to managing congestion. Prediction is never the goal, but the link between predictive performance and downstream decision-making performance is not straightforward: prioritizing a job based on predictions impacts the delay of other jobs!

We crystallize how classical tools from queueing theory provide managerial insights into the design and operation of AI-based service systems: i) simple policies with heavy traffic optimality guarantees, ii) novel model selection procedure for prediction models with downstream queueing performance as a central concern, and iii) AI-based triage by trading off predictive performance, hiring costs, and congestion costs.
-
AI-driven DecisionsarXiv:2406.06855 [math.OC], 2024Major revision in Management Science; Selected for presentation at SIG day 2025
Robust causality
Off-policy methods can learn sequential decision policies using the rich reservoir of previously collected (non-experimental / observational) data. While prediction models can be easily evaluated on previously collected data, assessing decision-making performance requires counterfactual reasoning. Traditional modeling assumptions that allow adjusting prediction models to learn counterfactuals rarely hold in practice. The growth in the nominal volume of data is no panacea: observed data typically only covers a portion of the state-action space, posing challenges in counterfactual learning. Concomitant to unseen data sparsity, shifts in the data distribution are common. Observed decisions depend on unrecorded confounders, and learning good policies requires causal reasoning. Marginalized demographic groups are severely underrepresented; for example, among 10000+ cancer clinical trials the National Cancer Institute funds, fewer than 5% of participants were non-white.
Our existing statistical language falls woefully short as it relies on unverifiable (and often false) assumptions, and we lack diagnostics that can identify failure modes. We develop data analysis tools that can guarantee robust scientific findings and perhaps more importantly, fail in expected ways by highlighting the fundamental epistemic uncertainty in the data.
External validity
While large-scale randomized studies offer a “gold standard” for internal validity, their external validity can be called into question over spatiotemporal changes in the population, particularly when the treatment effect is heterogeneous across the population. To assess and improve external validity, we develop sensitivity analysis frameworks that allows researchers to assess the extent to which existing experiments inform the treatment effect in a new target site and quantify an expected range of the policy effect for each new site.
Unobserved confounding
Off-policy methods can learn decision policies using the rich reservoir of previously collected (observational) data. A universal assumption that enable counterfactual reasoning requires observed decisions do not depend on any unrecorded confounders that simultaneously affect future states/rewards. This condition is frequently violated in medicine, e-commerce, and public policy, e.g., emergency department patients often do not have an existing record in the hospital’s electronic health system, leaving essential patient-specific information unobserved in subsequent counterfactual analysis.
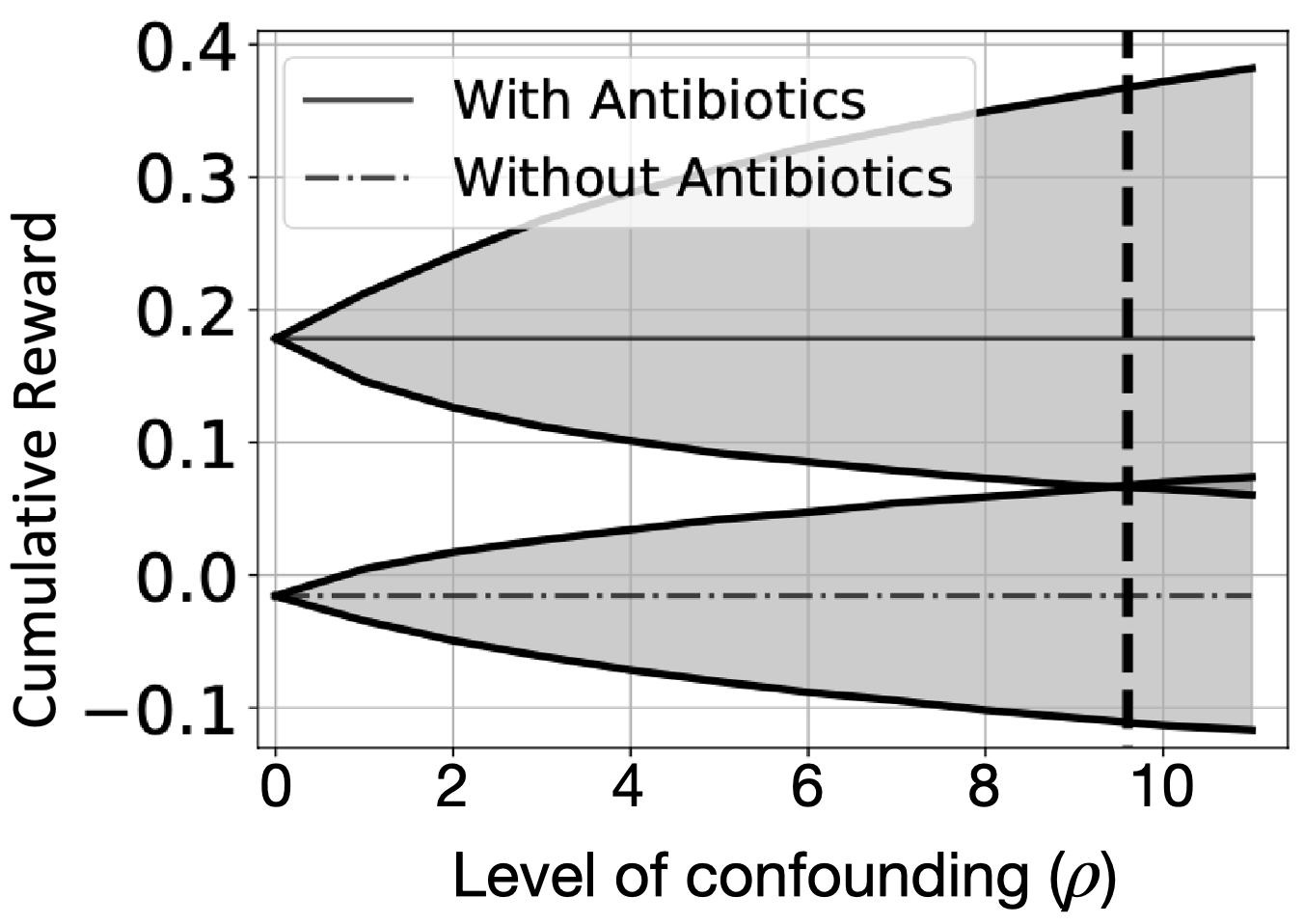
In the presence of unobserved confounding, even with large samples, it is impossible to precisely estimate the performance of the evaluation policy. To guard against spurious counterfactual evaluations, we propose a worst-case approach where we first posit a realistic notion of bounded unobserved confounding that limits the influence of unrecorded variables on observed decisions and develop corresponding worst-case bounds on the reward.
-
Robust CausalityAnnals of Statistics, 2022
Research philosophy
While theoretical insights can provide invaluable principles, their successful operationalization requires recognizing and internalizing the limitations of crude approximations and unverifiable assumptions we put in place for mathematical convenience. My group’s research methodology aims to connect two disparate yet complementary worldviews:
- computational tools and mathematical insights from statistical learning, optimization, applied probability, and casual inference
- rigorous empirical benchmarking practices arising from the AI research community’s data-centric approach.
We take inspiration from Von Neumann’s perspective on mathematical sciences as paraphrased below:
As a mathematical discipline travels far from its empirical source only indirectly inspired from ideas coming from 'reality', it is beset with grave dangers that it will develop along the line of least resistance and become more and more purely aestheticizing. This need not be bad if the discipline is under the influence of researchers with an exceptionally well-developed taste, but the only general remedy is the rejuvenating return to the source: the reinjection of directly empirical ideas. I am convinced that this is a necessary condition to conserve the freshness and the vitality of the subject, and that this will remain so in the future.
Our methodological research is grounded in theoretical principles, but we do not view aesthetic mathematical results as the goal of our impact-driven agenda. We interweave empirical ideas in our algorithmic research, and recognize empirical rigour as a core part of the scientific method (induction). Correspondingly, we are passionate to build empirical foundations for the research community.
-
AI-driven DecisionsIn Advances in Neural Information Processing Systems 37, Datasets and Benchmark Track , 2024
-
AI-driven DecisionsarXiv:2408.04531 [cs.LG], 2024
-
Trustworthy AIIn In International Conference on Learning Representations, 2025 , 2025